一、ORM介绍
- orm英文全称object relational mapping,就是对象映射关系程序,简单来说我们类似python这种面向对象的程序来说一切皆对象。
- 但是我们使用的数据库却都是关系型的,为了保证一致的使用习惯,通过orm将编程语言的对象模型和数据库的关系模型建立映射关系,这样我们在使用编程语言对数据库进行操作的时候可以直接使用编程语言的对象模型进行操作就可以了,而不用直接使用sql语言。
1. orm的优点
- 隐藏了数据访问细节,“封闭”的通用数据库交互,ORM的核心。他使得我们的通用数据库交互变得简单易行,并且完全不用考虑该死的SQL语句。快速开发,由此而来。
- ORM使我们构造固化数据结构变得简单易行。
2. orm的缺点
- 无可避免的,自动化意味着映射和关联管理,代价是牺牲性能(早期,这是所有不喜欢ORM人的共同点)。
- 现在的各种ORM框架都在尝试使用各种方法来减轻这块(LazyLoad,Cache),效果还是很显著的。
二、安装sqlalchemy
pip install sqlalchemy
三、sqlalchemy基本使用
1. 创建数据库连接格式说明
- sqlite创建数据库连接就是创建数据库,而其他mysql等应该是需要数据库已存在才能创建数据库连接;建立数据库连接本文中有时会称为建立数据库引擎。
2. sqlite创建数据库连接
- 以相对路径形式,在当前目录下创建数据库格式如下
engine = create_engine('sqlite:///foo.db')
- 以绝对路径形式创建数据库,格式如下
#Unix/Mac - 4 initial slashes in total
engine = create_engine('sqlite:////absolute/path/to/foo.db')
#Windows
engine = create_engine('sqlite:///C:\\path\\to\\foo.db')
#Windows alternative using raw string
engine = create_engine(r'sqlite:///C:\path\to\foo.db')
- sqlite可以创建内存数据库(其他数据库不可以),格式如下
# format 1
engine = create_engine('sqlite://')
# format 2
engine = create_engine('sqlite:///:memory:', echo=True)
3. 其他数据库创建数据库连接
- PostgreSQL
# default
engine = create_engine('postgresql://scott:tiger@localhost/mydatabase')
# psycopg2
engine = create_engine('postgresql+psycopg2://scott:tiger@localhost/mydatabase')
# pg8000
engine = create_engine('postgresql+pg8000://scott:tiger@localhost/mydatabase')
- Mysql
# default
engine = create_engine('mysql://scott:tiger@localhost/foo')
# mysql-python
engine = create_engine('mysql+mysqldb://scott:tiger@localhost/foo')
# MySQL-connector-python
engine = create_engine('mysql+mysqlconnector://scott:tiger@localhost/foo')
# OurSQL
engine = create_engine('mysql+oursql://scott:tiger@localhost/foo')
- Oracle
engine = create_engine('oracle://scott:tiger@127.0.0.1:1521/sidname')
engine = create_engine('oracle+cx_oracle://scott:tiger@tnsname')
- MSSQL
# pyodbc
engine = create_engine('mssql+pyodbc://scott:tiger@mydsn')
# pymssql
engine = create_engine('mssql+pymssql://scott:tiger@hostname:port/dbname')
4. 创建数据库连接
from sqlalchemy import create_engine
engine = create_engine('sqlite:///foo.db?check_same_thread=False', echo=True)
# echo=Ture----echo默认为False,表示不打印执行的SQL语句等较详细的执行信息,改为Ture表示让其打印
# check_same_thread=False----sqlite默认建立的对象只能让建立该对象的线程使用,而sqlalchemy是多线程的所以我们需要指定
# check_same_thread=False来让建立的对象任意线程都可使用。否则不时就会报错
5. 定义映射
- 先建立基本映射类,后边真正的映射类都要继承它
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
- 然后创建真正的映射类,我们这里以一下User映射类为例,我们设置它映射到users表
- 首先要明确,ORM中一般情况下表是不需要先存在的反而为了类与表对应无误借助通过映射类来创建;当然表已戏存在了也无可以,在下一小结中你可以自己决定如果表存在时要如何操作是重新创建还是使用已有表,但使用已有表你需要确保和类的变量名与表的各字段名要对得上
from sqlalchemy import Column, Integer, String
# 定义映射类User,其继承上一步创建的Base
class User(Base):
# 指定本类映射到users表
__tablename__ = 'users'
# 如果有多个类指向同一张表,那么在后边的类需要把extend_existing设为True,表示在已有列基础上进行扩展
# 或者换句话说,sqlalchemy允许类是表的字集
# __table_args__ = {'extend_existing': True}
# 如果表在同一个数据库服务(datebase)的不同数据库中(schema),可使用schema参数进一步指定数据库
# __table_args__ = {'schema': 'test_database'}
# 各变量名一定要与表的各字段名一样,因为相同的名字是他们之间的唯一关联关系
# 从语法上说,各变量类型和表的类型可以不完全一致,如表字段是String(64),但我就定义成String(32)
# 但为了避免造成不必要的错误,变量的类型和其对应的表的字段的类型还是要相一致
# sqlalchemy强制要求必须要有主键字段不然会报错,如果要映射一张已存在且没有主键的表,那么可行的做法是将所有字段都设为primary_key=True
# 不要看随便将一个非主键字段设为primary_key,然后似乎就没报错就能使用了,sqlalchemy在接收到查询结果后还会自己根据主键进行一次去重
# 指定id映射到id字段; id字段为整型,为主键,自动增长(其实整型主键默认就自动增长)
id = Column(Integer, primary_key=True, autoincrement=True)
# 指定name映射到name字段; name字段为字符串类形,
name = Column(String(20))
fullname = Column(String(32))
password = Column(String(32))
# __repr__方法用于输出该类的对象被print()时输出的字符串,如果不想写可以不写
def __repr__(self):
return "<User(name='%s', fullname='%s', password='%s')>" % (
self.name, self.fullname, self.password)
- 在上面的定义我__tablename__属性是写死的,但有时我们可能想通过外部给类传递表名,此时可以通过以下变通的方法来实现
def get_dynamic_table_name_class(table_name):
# 定义一个内部类
class TestModel(Base):
# 给表名赋值
__tablename__ = table_name
__table_args__ = {'extend_existing': True}
username = Column(String(32), primary_key=True)
password = Column(String(32))
# 把动态设置表名的类返回去
return TestModel
6. 创建数据表
# 查看映射对应的表
User.__table__
# 创建数据表。一方面通过engine来连接数据库,另一方面根据哪些类继承了Base来决定创建哪些表
# checkfirst=True,表示创建表前先检查该表是否存在,如同名表已存在则不再创建。其实默认就是True
Base.metadata.create_all(engine, checkfirst=True)
# 上边的写法会在engine对应的数据库中创建所有继承Base的类对应的表,但很多时候很多只是用来则试的或是其他库的
# 此时可以通过tables参数指定方式,指示仅创建哪些表
# Base.metadata.create_all(engine,tables=[Base.metadata.tables['users']],checkfirst=True)
# 在项目中由于model经常在别的文件定义,没主动加载时上边的写法可能写导致报错,可使用下边这种更明确的写法
# User.__table__.create(engine, checkfirst=True)
# 另外我们说这一步的作用是创建表,当我们已经确定表已经在数据库中存在时,我完可以跳过这一步
# 针对已存放有关键数据的表,或大家共用的表,直接不写这创建代码更让人心里踏实
例子
- sql原生语句创建表
CREATE TABLE user (
id INTEGER NOT NULL AUTO_INCREMENT,
name VARCHAR(32),
password VARCHAR(64),
PRIMARY KEY (id)
)
- orm,实现上面同样的功能,代码如下
第1种创建表结构的方法
# table_structure.py
import sqlalchemy
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String
engine = create_engine("mysql+pymysql://root:yun258762@localhost/test_db",
encoding='utf-8', echo=True)
Base = declarative_base() # 生成orm基类
class User(Base):
__tablename__ = 'user' # 表名
id = Column(Integer, primary_key=True)
name = Column(String(32))
password = Column(String(64))
Base.metadata.create_all(engine) # 创建表结构
注:懒惰连接 当create_engine()第一次返回时,引擎实际上还没有尝试连接到数据库; 只有在第一次要求它对数据库执行任务时才会发生这种情况
第2种创建表结构的方法
# table_structure.py
from sqlalchemy import Table, MetaData, Column, Integer, String, ForeignKey
from sqlalchemy.orm import mapper
from sqlalchemy import create_engine
metadata = MetaData()#生成metadata类
#创建user表,继承metadata类 #Engine使用Schama Type创建一个特定的结构对象
user = Table('new_user', metadata,
Column('id', Integer, primary_key=True),
Column('name', String(50)),
Column('fullname', String(50)),
Column('password', String(12))
)
class User(object):
def __init__(self, name, fullname, password):
self.name = name
self.fullname = fullname
self.password = password
#表元数据是使用Table构造单独创建的,然后通过mapper()函数与User类相关联
mapper(User,
user)
# 通过ConnectionPooling 连接数据库
engine = create_engine("mysql+pymysql://root:yun258762@localhost/test_db?charset=utf8", max_overflow=5, echo=True)
# 通过Dialect执行SQL
metadata.create_all(engine) #创建表结构
事实上,我们用第1种方式创建的表就是基于第2种方式的再封装
四、根据已有的表来自动生成model代码
1. 安装sqlacodegen
pip install sqlacodegen
2. sqlacodegen生成model
# linux应该被安装在/usr/local/bin/sqlacodegen
# mysql+pymysql示例
# 可使用--tables指定要生成model的表,不指定时为所有表都生成model
# 可使用--outfile指定代码输出到的文件,不指定时输出到stdout
# 注意只有当表有主键时sqlacodegen才生成如下的class,不然会使用旧的生成Table()类实例的形式
# 更多说明可使用-h参看
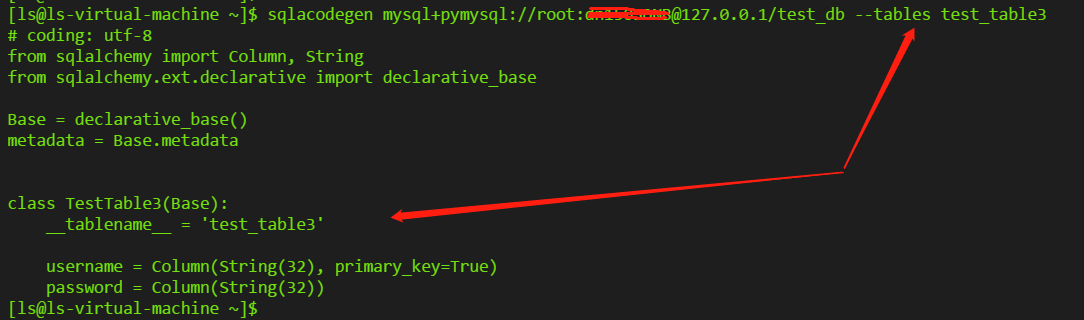
sqlacodegen mysql+pymysql://user:password@localhost/dbname [--tables table_name1,table_name2] [--outfile model.py]
- 如我的一个示例操作如下,成功为指定表生成model
五、数据操作
1. 增加数据
import table_structure#导入表结构模块
from sqlalchemy.orm import sessionmaker
Session_class = sessionmaker(bind=table_structure.engine) # 创建与数据库的会话session class ,注意,这里返回给session的是个class,不是实例
Session = Session_class() # 生成session实例#cursor
user_obj = table_structure.User(name="王昭君", password="123456") # 生成你要创建的数据对象
user_obj2 = table_structure.User(name="韩信", password="123456") # 生成你要创建的数据对象
#print(user_obj.name, user_obj.id) # 此时还没创建对象呢,不信你打印一下id发现还是None
#print(user_obj.name, user_obj.id) # 此时也依然还没创建
Session.add(user_obj) # 把要创建的数据对象添加到这个session里, 一会统一创建
Session.add(user_obj2) # 把要创建的数据对象添加到这个session里, 一会统一创建
或者
session.add_all([user_obj, user_obj2]) # 一次插入多条记录形式
Session.commit() # 现此才统一提交,创建数据
- 效果
mysql> select * from user;
+----+-------------+----------+
| id | name | password |
+----+-------------+----------+
| 1 | 王昭君 | 123456 |
| 2 | 韩信 | 123456 |
+----+-------------+----------+
2 rows in set (0.00 sec)
2. 查找数据
import table_structure#导入表结构模块
from sqlalchemy.orm import sessionmaker
Session_class = sessionmaker(bind=table_structure.engine) # 创建与数据库的会话session class ,注意,这里返回给session的是个class,不是实例
Session = Session_class() # 生成session实例#cursor
#查找所有数据
data1 = Session.query(table_structure.User).filter_by().all()
#查找第一个数据
data2 = Session.query(table_structure.User).filter_by().first()
#查找id=1的数据
data3= Session.query(table_structure.User).filter_by(id=1).all()
#查找id=2的数据
data4 = Session.query(table_structure.User).filter(table_structure.User.id ==2).all()
#查找id>1的所有数据
data5 = Session.query(table_structure.User).filter(table_structure.User.id>1).all()
#多条件查询,id>0&id<2的数据
data6 = Session.query(table_structure.User).filter(table_structure.User.id>0).filter(table_structure.User.id<2).all()
print('data1:',data1)
print('data2:',data2)
print('data3:',data3)
print('data4:',data4)
print('data5:',data5)
print('data6:',data6)
- 效果
data1: [<1 name:王昭君>, <2 name:韩信>]
data2: <1 name:王昭君>
data3: [<1 name:王昭君>]
data4: [<2 name:韩信>]
data5: [<2 name:韩信>]
data6: [<1 name:王昭君>]
3. 修改数据
import table_structure#导入表结构模块
from sqlalchemy.orm import sessionmaker
Session_class = sessionmaker(bind=table_structure.engine) # 创建与数据库的会话session class ,注意,这里返回给session的是个class,不是实例
Session = Session_class() # 生成session实例#cursor
data = Session.query(table_structure.User).filter_by(name="王昭君").first()#修改数据
data.name = "妲己"#将王昭君修改为妲己
data.password = '654321'
Session.commit()
- 效果
mysql> select * from user;
+----+-------------+----------+
| id | name | password |
+----+-------------+----------+
| 1 | 妲己 | 654321 |
| 2 | 韩信 | 123456 |
+----+-------------+----------+
2 rows in set (0.00 sec)
4.回滚
#回滚,类似于事物
import table_structure#导入表结构模块
from sqlalchemy.orm import sessionmaker
Session_class = sessionmaker(bind=table_structure.engine) # 创建与数据库的会话session class ,注意,这里返回给session的是个class,不是实例
Session = Session_class() # 生成session实例#cursor
user_obj = table_structure.User(name="老夫子", password="123456") # 生成你要创建的数据对象
user_obj2 = table_structure.User(name="雅典娜", password="123456") # 生成你要创建的数据对象
Session.add(user_obj) # 把要创建的数据对象添加到这个session里, 一会统一创建
Session.add(user_obj2) # 把要创建的数据对象添加到这个session里, 一会统一创建
print(Session.query(table_structure.User.name).filter(table_structure.User.name.in_(['老夫子','雅典娜'])).all())
print('--------------after rollback---------------:')
Session.rollback()
print(Session.query(table_structure.User.name).filter(table_structure.User.name.in_(['老夫子','雅典娜'])).all())
Session.commit()#现在才统一提交修改数据
- 效果
[('老夫子',), ('雅典娜',)]
--------------after rollback---------------:
[]
5. 删除数据
import table_structure#导入表结构模块
from sqlalchemy.orm import sessionmaker
Session_class = sessionmaker(bind=table_structure.engine) # 创建与数据库的会话session class ,注意,这里返回给session的是个class,不是实例
Session = Session_class() # 生成session实例#cursor
data = Session.query(table_structure.User).filter_by(name="妲己").first()#获取数据
Session.delete(data)#删除数据
Session.commit()
- 效果
mysql> select * from user;
+----+-------------+----------+
| id | name | password |
+----+-------------+----------+
| 2 | 韩信 | 123456 |
+----+-------------+----------+
1 rows in set (0.00 sec)
6. 统计和分组
- 统计
import table_structure#导入表结构模块
from sqlalchemy.orm import sessionmaker
Session_class = sessionmaker(bind=table_structure.engine) # 创建与数据库的会话session class ,注意,这里返回给session的是个class,不是实例
Session = Session_class() # 生成session实例#cursor
print(Session.query(table_structure.User).filter(table_structure.User.name.in_(['韩信'])).count())#mysql 默认大小写是一样的,如 'hello'=='HELLO'
Session.commit()#现在才统一提交修改数据
- 效果
1
- 分组
import table_structure#导入表结构模块
from sqlalchemy.orm import sessionmaker
Session_class = sessionmaker(bind=table_structure.engine) # 创建与数据库的会话session class ,注意,这里返回给session的是个class,不是实例
Session = Session_class() # 生成session实例#cursor
from sqlalchemy import func
print(Session.query(table_structure.User.name,func.count(table_structure.User.name)).group_by(table_structure.User.name).all())
Session.commit()#现在才统一提交修改数据
- 效果
[('韩信', 1)]
7. 外键关联
- 创建两个表,student2,study_record
# table_struct.py
#Author:Yun
#连表操作
import sqlalchemy
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String,DATE,ForeignKey
from sqlalchemy.orm import sessionmaker,relationship
engine = create_engine("mysql+pymysql://root:yun258762@localhost/test_db",
encoding='utf-8')
Base = declarative_base() # 生成orm基类
class Student(Base):
__tablename__ = 'student2' # 表名
id = Column(Integer, primary_key=True)
name = Column(String(32),nullable=False)
register_date = Column(DATE,nullable=False)
def __repr__(self):
return "<%s name:%s>" % (self.id,self.name)
class stu_record(Base):
__tablename__ = 'study_record'
id = Column(Integer,primary_key=True)
day = Column(Integer,nullable=False)
status = Column(String(32),nullable=False)
stu_id = Column(Integer,ForeignKey('student2.id'))
# stu_obj = query(id=1)
# student = query(Student).filter(Student.id == stu_obj.stu_id).first()
#只是在内存中建立关联关系
#允许在stu_record表中用字段self.student.name查询Student表中的数据
#stu_obj2 = Session.query(Student).filter(Student.name == 'luban1').first()
#允许在Student表中用字段stu_obj2.my_study_record查询stu_record表中的数据
student = relationship('Student',backref='my_study_record')
def __repr__(self):
return "<%s day:%s status:%s>" % (self.student.name,self.day,self.status)
Base.metadata.create_all(engine) # 创建表结构
- 为表添加数据
import table_struct#导入刚刚创建的表结构
from sqlalchemy.orm import sessionmaker
Session_class = sessionmaker(bind=table_struct.engine) # 创建与数据库的会话session class ,注意,这里返回给session的是个class,不是实例
Session = Session_class() #生成session实例#cursor
s1 = table_struct.Student(name='学员A',register_date='2015-11-29')
s2 = table_struct.Student(name='学员B',register_date='2016-11-29')
s3 = table_struct.Student(name='学员C',register_date='2017-11-29')
s4 = table_struct.Student(name='学员D',register_date='2018-11-29')
stu_obj1 = table_struct.stu_record(day=1,status='Yes',stu_id=5)
stu_obj2 = table_struct.stu_record(day=2,status='Yes',stu_id=5)
stu_obj3 = table_struct.stu_record(day=2,status='Yes',stu_id=6)
stu_obj4 = table_struct.stu_record(day=3,status='No',stu_id=6)
Session.add_all([s1,s2,s3,s4,stu_obj1,stu_obj2,stu_obj3,stu_obj4])
Session.commit()#现在才统一提交修改数据
- 跨表查询
#连表
import table_struct#导入刚刚创建的表结构
from sqlalchemy.orm import sessionmaker
Session_class = sessionmaker(bind=table_struct.engine) # 创建与数据库的会话session class ,注意,这里返回给session的是个class,不是实例
Session = Session_class()#生成session实例#cursor
#跨表查询
stu_obj = Session.query(table_struct.Student).filter(table_struct.Student.name=='学员A').first()
print(stu_obj.my_study_record)
Session.commit()#现在才统一提交修改数据
- 效果
[<学员A day:1 status:Yes>, <学员A day:2 status:Yes>]
六、多外键关联
- 处理的最常见情况之一是两个表之间有多个外键路径。考虑一个Customer类,它包含Address类的两个外键
- 下表中,Customer表有2个字段都关联了Address表
import sqlalchemy
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String,DATE,ForeignKey
from sqlalchemy.orm import relationship
engine = create_engine("mysql+pymysql://root:yun258762@192.168.176.139/test_db",
encoding='utf-8')
Base = declarative_base() # 生成orm基类
class Customer(Base):
__tablename__ = 'customer' # 表名
id = Column(Integer, primary_key=True)
name = Column(String(32),nullable=False)
builling_address_id = Column(Integer,ForeignKey('address.id'))
shipping_address_id = Column(Integer,ForeignKey('address.id'))
builling_address = relationship("Address",foreign_keys=[builling_address_id])
shipping_address = relationship("Address",foreign_keys=[shipping_address_id])
def __repr__(self):
return "<%s name:%s>" % (self.id,self.name)
class Address(Base):
__tablename__ = 'address'
id = Column(Integer,primary_key=True)
street = Column(String(64),nullable=False)
city = Column(String(64),nullable=False)
state = Column(String(64),nullable=False)
def __repr__(self):
return self.street
Base.metadata.create_all(engine) # 创建表结构
- 添加数据,并跨表查询
#同一张表里关联另一个表里的两个地址
import orm_fk
from sqlalchemy.orm import sessionmaker
Session_class = sessionmaker(bind=orm_fk.engine)#创建于数据
session = Session_class()#生成session实例 #cursor
add1 = orm_fk.Address(street='中路',city='艾欧尼亚',state='召唤师峡谷' )
add2 = orm_fk.Address(street='上路',city='艾欧尼亚',state='召唤师峡谷' )
add3 = orm_fk.Address(street='下路',city='艾欧尼亚',state='召唤师峡谷' )
session.add_all([add1,add2,add3])
c1 = orm_fk.Customer(name='鲁班',builling_address=add1,shipping_address=add1)
c2 = orm_fk.Customer(name='卡莎',builling_address=add1,shipping_address=add2)
c3 = orm_fk.Customer(name='妖姬',builling_address=add2,shipping_address=add3)
#为表添加数据
#session.add_all([c1,c2,c3])
obj = session.query(orm_fk.Customer).filter(orm_fk.Customer.name=='妖姬').first()
print(obj.name,obj.builling_address,obj.shipping_address)
session.commit()
- 效果
妖姬 上路 下路
七、多对多关系
- 现在来设计一个能描述“图书”与“作者”的关系的表结构,需求是
- 一本书可以有好几个作者一起出版
- 一个作者可以写好几本书
- 思维构图
一本书----》多个作者;一个作者-----》多本书
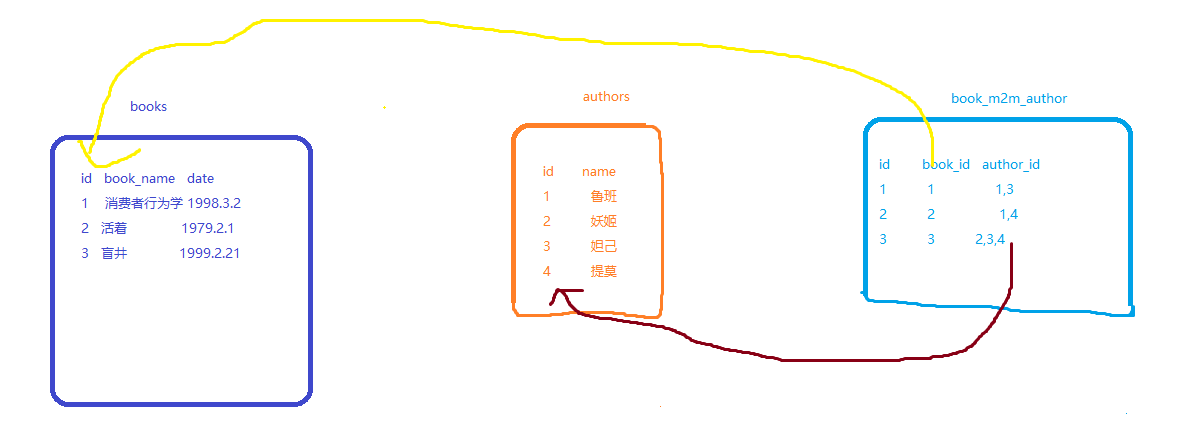
- 这样就相当于通过book_m2m_author表完成了book表和author表之前的多对多关联
from sqlalchemy import Table, Column, Integer,String,DATE, ForeignKey
from sqlalchemy.orm import relationship
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
engine = create_engine("mysql+pymysql://root:yun258762@localhost/test_db?charset=utf8",
)
Base = declarative_base()
#通orm自动维护这表,所以不需要用类方法创建,映射
book_m2m_author = Table('book_m2m_author', Base.metadata,
Column('book_id',Integer,ForeignKey('books.id')),
Column('author_id',Integer,ForeignKey('authors.id')),
)
class Book(Base):
__tablename__ = 'books'
id = Column(Integer,primary_key=True)
name = Column(String(64))
pub_date = Column(DATE)
authors = relationship('Author',secondary=book_m2m_author,backref='books')
def __repr__(self):
return "<book_name:%s date:%s>" % (self.name,self.pub_date)
class Author(Base):
__tablename__ = 'authors'
id = Column(Integer, primary_key=True)
name = Column(String(32))
def __repr__(self):
return "<author:%s>" %self.name
Base.metadata.create_all(engine) # 创建表结构
- 创建几本书和作者
import orm_fk
from sqlalchemy.orm import sessionmaker
Session_class = sessionmaker(bind=orm_fk.engine)#创建于数据
session = Session_class()
b1 = orm_fk.Book(name='消费者行为学',pub_date='2018-11-29')
b2 = orm_fk.Book(name='活着',pub_date='2018-11-29')
b3 = orm_fk.Book(name='盲井',pub_date='2018-11-29')
a1 = orm_fk.Author(name='鲁班')
a2 = orm_fk.Author(name='妖姬')
a3 = orm_fk.Author(name='妲己')
a4 = orm_fk.Author(name='提莫')
b1.authors = [a1,a3]
b2.authors = [a2,a4]
b3.authors = [a1,a2,a3]
session.add_all([b1,b2,b3,a1,a2,a3])
session.commit()
- 效果
mysql> select * from authors;
+----+--------+
| id | name |
+----+--------+
| 1 | 鲁班 |
| 2 | 妖姬 |
| 3 | 提莫 |
| 4 | 妲己 |
+----+--------+
4 rows in set (0.00 sec)
mysql> select * from books;
+----+--------------------+------------+
| id | name | pub_date |
+----+--------------------+------------+
| 1 | 消费者行为学 | 2018-11-29 |
| 2 | 盲井 | 2018-11-29 |
| 3 | 活着 | 2018-11-29 |
+----+--------------------+------------+
3 rows in set (0.00 sec)
mysql> select * from book_m2m_author;
+---------+-----------+
| book_id | author_id |
+---------+-----------+
| 1 | 1 |
| 1 | 4 |
| 2 | 1 |
| 2 | 2 |
| 2 | 4 |
| 3 | 2 |
| 3 | 3 |
+---------+-----------+
7 rows in set (0.00 sec)
- 用orm查数据
import orm_fk
from sqlalchemy.orm import sessionmaker
Session_class = sessionmaker(bind=orm_fk.engine)#创建于数据
session = Session_class()
print('----通过作者表查关联的书-------')
author_obj = session.query(orm_fk.Author).filter(orm_fk.Author.name=='鲁班').first()
print(author_obj.books)
print('----通过书表查看关联的作者-------')
book_obj = session.query(orm_fk.Book).filter(orm_fk.Book.id==1).first()
print(book_obj.authors)
session.commit()
- 效果
----通过作者表查关联的书-------
[<book_name:消费者行为学 date:2018-11-29>, <book_name:盲井 date:2018-11-29>]
----通过书表查看关联的作者-------
[<author:鲁班>, <author:妲己>]
- 多对多删除
删除数据时不用管boo_m2m_authors , sqlalchemy会自动帮你把对应的数据删除 通过书删除作者
import orm_fk
from sqlalchemy.orm import sessionmaker
Session_class = sessionmaker(bind=orm_fk.engine)#创建于数据
session = Session_class()
author_obj = session.query(orm_fk.Author).filter_by(name="鲁班").first()
book_obj = session.query(orm_fk.Book).filter_by(name="盲井").first()
book_obj.authors.remove(author_obj) # 从一本书里删除一个作者
session.commit()
- 效果
删除之前:
mysql> select * from book_m2m_author;
+---------+-----------+
| book_id | author_id |
+---------+-----------+
| 1 | 1 |
| 1 | 4 |
| 2 | 1 |
| 2 | 2 |
| 2 | 4 |
| 3 | 2 |
| 3 | 3 |
+---------+-----------+
7 rows in set (0.00 sec)
删除之后:
mysql> select * from book_m2m_author;
+---------+-----------+
| book_id | author_id |
+---------+-----------+
| 1 | 1 |
| 1 | 4 |
| 2 | 2 |
| 2 | 4 |
| 3 | 2 |
| 3 | 3 |
+---------+-----------+
6 rows in set (0.00 sec)
- 直接删除作者
删除作者时,会把这个作者跟所有书的关联关系数据也自动删除
import orm_fk
from sqlalchemy.orm import sessionmaker
Session_class = sessionmaker(bind=orm_fk.engine)#创建于数据
session = Session_class()
author_obj =session.query(orm_fk.Author).filter_by(name="鲁班").first()
print(author_obj.name , author_obj.books)
session.delete(author_obj)
session.commit()
- 效果
mysql> select * from book_m2m_author;
+---------+-----------+
| book_id | author_id |
+---------+-----------+
| 1 | 1 |
| 1 | 4 |
| 2 | 2 |
| 2 | 4 |
| 3 | 2 |
| 3 | 3 |
+---------+-----------+
6 rows in set (0.00 sec)
mysql> select * from book_m2m_author;
+---------+-----------+
| book_id | author_id |
+---------+-----------+
| 1 | 4 |
| 2 | 2 |
| 2 | 4 |
| 3 | 2 |
| 3 | 3 |
+---------+-----------+
5 rows in set (0.00 sec)