论文名称:SynthTIGER: Synthetic Text Image GEneratoR Towards Better Text Recognition Models
论文地址:https://arxiv.org/abs/2107.09313
开源代码:https://github.com/clovaai/synthtiger
开源数据:https://github.com/clovaai/synthtiger#datasets
blend_modes模式介绍: https://en.wikipedia.org/w/index.php?title=Blend_modes&oldid=747749280
一、简介
该论文提出了一种新的文本图片合成方法——SynthTIGER。该合成方法在单一算法框架下整合了有效的合成技术。同时,该论文还提出了两种算法分别解决文本长度上的长尾问题和训练集中的字符分布问题。通过实验,作者验证了SynthTIGER相较于先前的文本图片合成方法,在场景文本识别任务中表现更好。
二、研究背景
在深度学习时代,通过使用大量文本图片进行训练,OCR模型获得了显著的性能提升。通过算法合成文本图片,能够在短时间内得到大量的训练数据。而获取同等数量的真实文本图片则需要花费大量的成本进行采集和标注。
该论文提出的文本图片合成方法是用于场景文本识别任务中的。场景文本识别任务的训练数据是包含若干个字符的文本行图像,该任务要求合成数据覆盖在现实世界中可能存在的各种样式和文本内容。
在先前的合成方法中比较经典的是MJ[1]和ST[2](这两种方法与SynthTIGER合成图片的对比如图所示)。MJ是典型的文本行合成方法,在合成时不会像从场景图中直接裁切下来的文本行图片那样可能会引入额外的文本噪声。而ST可以合成包含多个文本行于一张图的场景文本图片,其裁切下来的文本行可能会引入来自于其他文本行的文本噪声。但是,由于ST需要选择特定的区域放置文本,因此文本的样式(如文本的大小)可能会受到限制。

该论文提出的SynthTIGER结合了MJ和ST的优势,在引入了文本噪声的同时文本的样式不再受到限制。使用SynthTIGER合成的数据训练识别器时,识别器的性能要比使用MJ或ST合成的数据训练的要好,同时性能也与MJ和ST合成数据联合训练处于同一水平。
该论文也提出了两种方法来缓解字符频率和文本长度在数据中出现偏斜分布的问题。
三、生成步骤
def generate(self):
quality = np.random.randint(self.quality[0], self.quality[1] + 1)
midground = np.random.rand() < self.midground
fg_color, fg_style, mg_color, mg_style, bg_color = self._generate_color()
fg_image, label, bboxes, glyph_fg_image, glyph_bboxes = self._generate_text(
fg_color, fg_style
)
bg_image = self._generate_background(fg_image.shape[:2][::-1], bg_color)
if midground:
mg_image, _, _, _, _ = self._generate_text(mg_color, mg_style)
mg_image = self._erase_image(mg_image, fg_image)
bg_image = _blend_images(mg_image, bg_image, self.visibility_check)
image = _blend_images(fg_image, bg_image, self.visibility_check)
image, fg_image, glyph_fg_image = self._postprocess_images(
[image, fg_image, glyph_fg_image]
)
data = {
"image": image,
"label": label,
"quality": quality,
"mask": fg_image[..., 3],
"bboxes": bboxes,
"glyph_mask": glyph_fg_image[..., 3],
"glyph_bboxes": glyph_bboxes,
}
return data
- 生成文本foreground和mid-ground两种格式的颜色及样式映射
- 通过foreground颜色和样式生成文本图片
- 通过self.color和self.texture生成背景
- 判断是否使用midground,如果使用通过blend_modes随机挑选方法进行两张图片的合成
- 使用blend_modes合并背景照片和字体照片
- 剩余其他的对图片的特殊处理
def apply(self, layers, meta=None):
meta = self.sample(meta)
for layer in layers:
image = np.empty(layer.image.shape)
image[..., :] = self.data(meta) //这里会把四维的向量赋值给image的每一行
layer.image = utils.blend_image(image, layer.image, mask=True)
四、算法详解
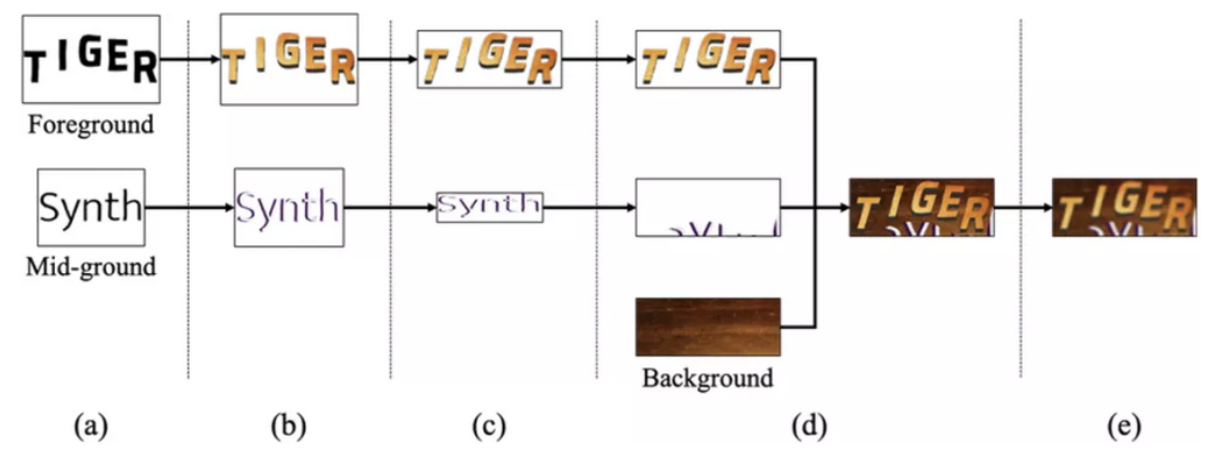 SynthTIGER的渲染步骤如图所示,下文将会对每个步骤进行介绍。
(a)文本形状选择:从字体库随机选择字体后,该步骤生成的文本排布方式分为两种:一种是字符从左到右排布,一种是抛物线曲线排布。
SynthTIGER的渲染步骤如图所示,下文将会对每个步骤进行介绍。
(a)文本形状选择:从字体库随机选择字体后,该步骤生成的文本排布方式分为两种:一种是字符从左到右排布,一种是抛物线曲线排布。
(b)文本样式选择:在字体颜色选择上,作者参考ST的方法,使用K-means聚类从真实文本行图片中收集文本颜色和背景颜色的搭配,作为选择文本颜色的依据。考虑到真实场景中的文本颜色并不是单一的,SynthTIGER还选择纹理填充文本。同时,文本的边框和阴影作者也有所考虑。
(c)变换:SynthTIGER主要提供了拉伸、梯形、倾斜和旋转四种变换方式,并随机选择文本距离边界的距离。
(d)融合:在融合阶段,算法需要得到前景文本、干扰文本和背景。前景文本和干扰文本通过前面的步骤生成,而背景生成是通过选择从颜色库和纹理库中随机选择颜色和纹理得到的。融合时,首先由背景和干扰文本融合得到新的背景,再将前景文本和新的背景融合。融合方法有正常、乘法、加网、叠加、强光、柔光、减淡、除法、加法、差值、仅变暗和仅变亮等。SynthTIGER还通过Flood-Fill算法来剔除掉文本和背景混淆的图片。
(e)后处理:SynthTIGER的后处理方法包括高斯噪声、高斯模糊、尺寸调整、中值模糊和JPEG压缩等。
SynthTIGER还提供了两种额外的策略来控制合成数据集的文本长度分布和字符分布。
文本长度分布控制策略是通过给定文本长度的分布,随机决定一个文本长度并随机采样一条文本。当文本长度超过预定时,截断文本;反之则重复采样文本拼接到原文本后面至长度大于等于预定长度,再进行截断。
字符分布控制策略通过给定字符出现概率的分布,随机决定一个字符,然后随机选择一个含有该字符的文本作为前景文本。
五、配置文件详解
# 基本输出设置
coord_output: true # 是否输出坐标
mask_output: true # 是否输出掩码
glyph_coord_output: true # 是否输出字形坐标
glyph_mask_output: true # 是否输出字形掩码
# 垂直设置和质量
vertical: false # 是否生成垂直方向的文本
quality: [50, 95] # 输出质量范围(用于控制图像或文本的质量)
visibility_check: true # 是否进行可见性检查
# 文本排布方式(从左向右)
midground: 0.0 # 应用概率
midground_offset:
percents: [[-0.5, 0.5], [-0.5, 0.5]]
foreground_mask_pad: 5
# 语料库设置
corpus:
weights: [1, 0]
args: # 具体语料库的路径、长度范围、大小写和增强设置。
# length augmentable corpus
- paths: [resources/corpus/mjsynth.txt, resources/corpus/synthtext.txt]
weights: [1, 1]
min_length: 1
max_length: 25
textcase: # [lower, upper, capitalize]
augmentation: 0 # 拼接增扩不同字符的文本到text中的概率
augmentation_length: [1, 25]
# char augmentable corpus
- paths: []
weights: []
min_length: 1
max_length: 25
textcase: [lower, upper, capitalize]
augmentation: 0
augmentation_charset: resources/charset/alphanum_special.txt
# 字体设置
font:
paths: [resources/font] # 字体文件路径
weights: [1] # 字体权重
size: [15, 15] # 字体大小范围
bold: 0.0 # 字体加粗比例
# 纹理设置
texture:
prob: 0.5 # 应用纹理的概率
args:
paths: [resources/image] # 纹理图片路径
weights: [1] # 纹理权重
alpha: [0.5, 1] # 纹理透明度范围
grayscale: 0 # 是否应用灰度
crop: 1 # 是否裁剪
colormap2:
paths: [resources/colormap/iiit5k_gray.txt]
weights: [1]
k: 2
alpha: [1, 1]
colorize: 1
# 色彩映射设置
colormap3:
paths: [resources/colormap/iiit5k_gray.txt] # 色彩映射文件路径
weights: [1] # 色彩映射权重
k: 3 # 色彩映射簇数
alpha: [1, 1] # 色彩透明度范围
colorize: 1 # 是否进行色彩化
# 颜色设置
color:
gray: [125, 125] # 灰度范围
alpha: [1, 1] # 透明度范围
colorize: 0 # 是否进行色彩化
# 字体扭曲变化
shape:
prob: 0.25
args:
weights: [1, 1]
args:
# elastic distortion
- alpha: [15, 30]
sigma: [9, 12]
# elastic distortion
- alpha: [0, 0.5]
sigma: [0, 0.3]
layout:
weights: [4, 1]
args:
# flow layout
- space: [0, 8]
line_align: [middle]
# curve layout
- curve: [5, 15]
space: [0, 5]
convex: 0.5
upward: 0.0
# 各种阴影
style:
prob: 0.0
args:
weights: [1, 2, 2]
args:
# text border
- size: [1, 12]
alpha: [1, 1]
grayscale: 0
# text shadow
- distance: [1, 6]
angle: [0, 360]
alpha: [0.3, 0.7]
grayscale: 0
# text extrusion
- length: [1, 12]
angle: [0, 360]
alpha: [1, 1]
grayscale: 0
# 字体的旋转变化
transform:
prob: 0.25
args:
weights: [1, 1, 1, 1, 1, 1, 1]
args:
# perspective x
- percents: [[0.5, 1], [1, 1]]
aligns: [[0, 0], [0, 0]]
# perspective y
- percents: [[1, 1], [0.5, 1]]
aligns: [[0, 0], [0, 0]]
# trapezoidate x
- weights: [1, 0, 1, 0]
percent: [0.75, 1]
align: [-1, 1]
# trapezoidate y
- weights: [1, 0, 1, 0]
percent: [0.9, 1]
align: [-1, 1]
# skew x
- weights: [1, 0]
angle: [0, 15]
ccw: 0.5
# skew y
- weights: [0, 1]
angle: [0, 5]
ccw: 0.5
# rotate
- angle: [0, 10]
ccw: 0.5
# 随机四周填充
pad:
prob: 0.5
args:
pxs: [[0, 10], [0, 10], [0, 10], [0, 10]] # 每个方向的填充像素范围
# 后处理设置
postprocess:
args:
# gaussian noise
- prob: 0.5
args:
scale: [4, 6]
per_channel: 0
# gaussian blur
- prob: 0.5
args:
sigma: [0, 1]
# resample
- prob: 0.1
args:
size: [0.4, 0.4]
# median blur
- prob: 0
args:
k: [1, 1]
六、总结和讨论
SynthTIGER与现有的合成数据集相比,在场景文本识别模型训练中取得了更好的表现,同时其合成函数的有效性也得到了验证。同时实验还表明该论文提出的文本长度分布控制策略和字符分布控制策略有助于学习更通用的场景文本识别模型。最后,作者通过提供开源合成引擎和新的合成数据集为OCR社区做出贡献。